Java学习笔记|修饰符和运算符
Java修饰符
Java运算符
数学建模|预测方法:神经元网络
人工神经网络是国际学术界十分活跃的前沿研究领域,在控制与优化,预测与管理,识别模式和图像处理、通信等方面都得到了广泛的应用。
Java学习笔记|变量
在java中,每个变量都有一个类型,声明变量类型时,变量的类型位于变量名前: 示例:
1 | double salary; |
声明变量的基本格式:
数学建模|预测方法:插值与拟合
为什么要插值拟合
在实际中,常常要处理由实验或测量所得到的一些离散数据。插值与拟合方法就是要通过这些数据去确定某一类未知的函数的参数或寻求某个近似函数,使所得到的近似函数与已知数据有较高的拟合精度。
插值
插值函数:存在简单易算的函数
数学建模|预测方法:马尔科夫预测
马尔可夫链的定义
现实世界中有很多这样的现象:某一个系统在已知现在的条件下,系统未来时刻的情况只与现在有关,而与过去的历史无关,比如,研究一个商店的累计销售额,如果现在时刻的累计销售额已知,则未来某一时刻的累计销售额与现在时刻以前的任一时刻累计销售额无关。描述这类随机现象的数学模型称为马尔可夫模型。
数学建模|预测方法:灰色预测模型
简介
灰色系统理论是由华中理工大学邓聚龙教授于1982年提出并加以发展的。二十几年来,引起了不少国内外学者的关注,得到了长足的发展。目前,在我国已经成为社会、经济、科学技术在等诸多领域进行预测、决策、评估、规划控制、系统分析与建模的重要方法之一。特别是它对时间序列短、统计数据少、信息不完全系统的分析与建模,具有独特的功效,因此得到了广泛的应用.
数学建模|预测方法:微分方程
微分方程预测特征
适用范围
适用于基于相关原理的因果预测模型,大多是物理或几何方面的典型问题,假设条件,用数学符号表示规律,列出方程,求解的结果就是问题的答案。
Java学习笔记|数据类型
数据类型
如下图,java的数据类型
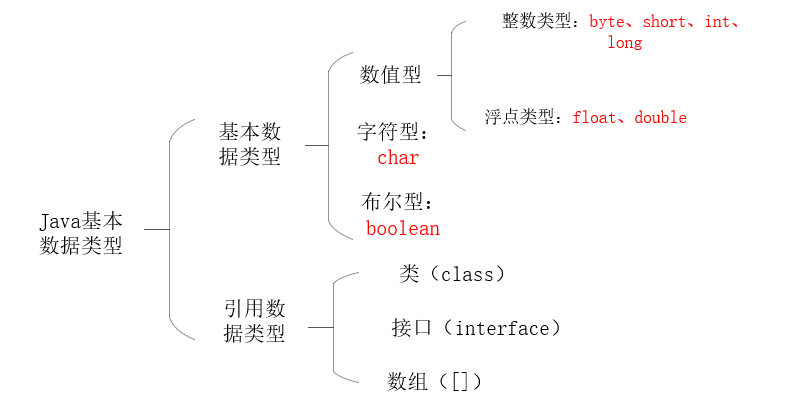
Java基本数据类型
其中:
- 整数类型:byte,1字节,8位,最大存储数据量是255,存放的数据范围是-128~127之间。
- 整数类型:short,2字节,16位,最大数据存储量是65536,数据范围是-32768~32767之间。
- 整数类型:int,4字节,32位,最大数据存储容量是2的32次方减1,数据范围是负的2的31次方到正的2的31次方减1。
- 整数类型:long,8字节,64位,最大数据存储容量是2的64次方减1,数据范围为负的2的63次方到正的2的63次方减1。
- 浮点类型:float,4字节,32位,数据范围在3.4e-45~1.4e38,直接赋值时必须在数字后加上f或F。
- 浮点类型:double,8字节,64位,数据范围在4.9e-324~1.8e308,赋值时可以加d或D也可以不加。
- 字符型:char,2字节,16位,存储Unicode码,用单引号赋值。
- 布尔型:boolean,只有true和false两个取值
Java学习笔记|基础语法
基础语法
一个 Java 程序可以认为是一系列对象的集合,而这些对象通过调用彼此的方法来协同工作。下面简要介绍下类、对象、方法和实例变量的概念。
- 对象:对象是类的一个实例,有状态和行为。例如,一条狗是一个对象,它的状态有:颜色、名字、品种;行为有:摇尾巴、叫、吃等。
- 类:类是一个模板,它描述一类对象的行为和状态。
- 方法:方法就是行为,一个类可以有很多方法。逻辑运算、数据修改以及所有动作都是在方法中完成的。
- 实例变量:每个对象都有独特的实例变量,对象的状态由这些实例变量的值决定。
数学建模|多元分析(二)
判别分析
判别问题用统计的语言来表达,就是已有
数学建模|多元分析(一)
多元分析是多变量的统计分析方法。
聚类分析
聚类分析一般分为Q型聚类分析和R型聚类分析。
- Q型聚类分析是指对样品进行聚类分析
- R型聚类分析是指对变量进行聚类。
根据处理方法的不同聚类分析又分为系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法。
数学建模|回归分析
什么是回归分析
人们关心的因变量受自变量的关联性(非因果性)的影响,并且存在众多随机因素,难以用机理分析方法找出它们之间的关系;需要建立这些变量的数学模型,使得能够根据自变量的数值预测因变量的大小,或者解释因变量的变化。
换句话说:回归分析是一种类相关性分析,就是通过分析已知数据和其造成的影响,来预测未知数据造成的影响。
一般来说,回归分析的主要步骤:
笔记|统计学习方法:逻辑斯蒂回归与最大熵
基本介绍
逻辑斯蒂回归(Logistic Regression),虽然被称为回归,其实是一种解决分类问题的算法。 LR模型是在线性模型的基础上,使用sigmoid激励函数,将线性模型的结果压缩到
数学建模|规划问题
线性规划
定义:
- 可行解:满足约束条件的解,使目标函数达到最大的可行解称为最优解。
- 可行域:所有可行解构成的集合。
MATLAB中线性规划的标准形式
1 | [x,fval]=linprog(f,A,b) |
x返回决策向量的取值,fval返回目标函数的最优值,A和b对应线性不等式约束;Aeq和beq对应线性等式约束;lb和ub分别对应决策向量的下界向量和上界向量。
笔记|统计学习方法:决策树(二)
决策树的剪枝
由于决策树的生成算法是递归实现的,所以对已知数据的分类十分准确,但对未知数据的预测就不那么准确,就产生了过拟合的现象。 所以就产生了一种将已生成的树进行简化的过程,称为:“剪枝”。
笔记|统计学习方法:决策树(一)
决策树的基本概念
决策树就是一棵树。
- 叶结点对应于决策结果,其他每个结点则对应于一个属性测试;
- 每个结点包含的样本集合根据属性测试的结果被划分到子结点中;
- 根结点包含样本全集,从根结点到每个叶子结点的路径对应了一个判定测试序列。 示例: